Multi-view Consistent Editing
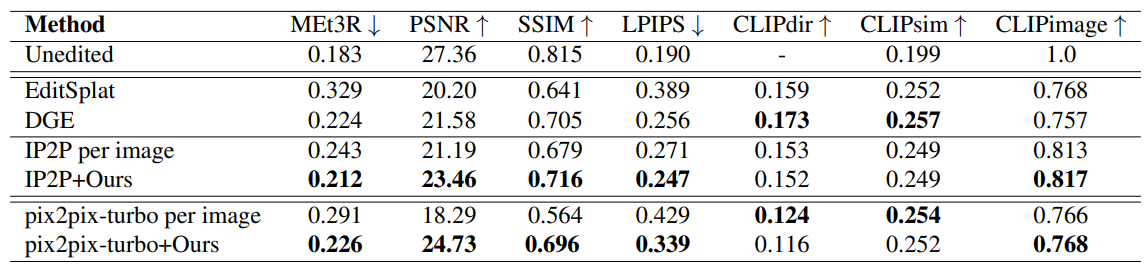
Image editing methods applied independently to multi-view images often produce inconsistent edits across views. Our method improves multi-view consistency by guiding the diffusion process to generate edited images with improved consistency.

We show that our method gives edited images with improved multi-view consistency compared to other state-of-the-art 3D editing methods (EditSplat and DGE).